Introduction to Big Data Management
In today’s digital age, data is being generated at an unprecedented rate. From social media posts to sensor data from IoT devices, the amount of data being created every day is staggering. This explosion of data has led to the emergence of a new field known as Big Data Management. But what exactly is Big Data, and what constitutes “big enough” for data management?
Defining Big Data
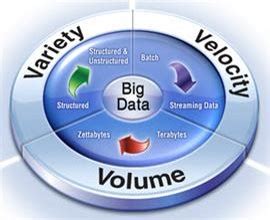
Big Data refers to datasets that are too large or complex to be handled by traditional data processing tools and techniques. These datasets are characterized by the “three Vs”:
- Volume: The sheer size of the data, often measured in terabytes or petabytes.
- Velocity: The speed at which data is generated and needs to be processed.
- Variety: The different types and formats of data, including structured, semi-structured, and unstructured data.
Some experts have added a fourth “V” to this list: Veracity, which refers to the quality and accuracy of the data.
The Importance of Big Data Management
As organizations collect and generate more and more data, the need for effective Big Data Management becomes increasingly critical. Without proper management, this data can quickly become overwhelming and unusable. Some of the key reasons why Big Data Management is important include:
- Insight and Decision-Making: By analyzing large datasets, organizations can gain valuable insights into customer behavior, market trends, and other key factors that can inform strategic decision-making.
- Competitive Advantage: Companies that can effectively manage and analyze their data are better positioned to identify new opportunities and stay ahead of the competition.
- Operational Efficiency: By automating data processing and analysis tasks, organizations can streamline their operations and reduce costs.
- Regulatory Compliance: Many industries are subject to strict data privacy and security regulations, and effective Big Data Management is essential for ensuring compliance.
The Challenges of Big Data Management
While the benefits of Big Data are clear, managing these massive datasets can be a daunting task. Some of the key challenges include:
Data Storage and Processing
One of the biggest challenges of Big Data Management is simply storing and processing the vast amounts of data being generated. Traditional databases and data processing tools are often not designed to handle datasets of this size and complexity. As a result, organizations must turn to new technologies such as distributed file systems (like Hadoop) and NoSQL databases that can scale horizontally across multiple servers.
Data Integration and Quality
Another challenge is integrating data from multiple sources and ensuring its quality. With data coming in from a variety of systems and formats, it can be difficult to ensure consistency and accuracy across the entire dataset. This requires robust data integration and cleansing processes to identify and correct errors and inconsistencies.
Data Security and Privacy
As organizations collect more and more sensitive data about their customers and operations, ensuring the security and privacy of this data becomes increasingly important. This requires strong access controls, encryption, and other security measures to prevent unauthorized access or breaches. It also requires compliance with a growing number of data privacy regulations such as GDPR and CCPA.
Skill Gaps and Talent Shortages
Finally, there is a significant skill gap when it comes to Big Data Management. The technologies and techniques involved are complex and constantly evolving, requiring specialized expertise that can be difficult to find. According to a recent survey by Gartner, the top barrier to the adoption of Big Data analytics is the lack of skilled personnel (Gartner, 2021).

Techniques and Technologies for Big Data Management
To address these challenges, organizations are turning to a variety of techniques and technologies for managing Big Data. Some of the most important include:
Distributed File Systems
Distributed file systems like Hadoop’s HDFS (Hadoop Distributed File System) allow data to be stored across multiple servers, providing scalability and fault tolerance. These systems break large files into smaller blocks that can be distributed across the cluster, allowing for parallel processing and faster data retrieval.
NoSQL Databases
NoSQL databases like MongoDB, Cassandra, and Couchbase are designed to handle large volumes of unstructured or semi-structured data. Unlike traditional relational databases, NoSQL databases do not require a fixed schema and can scale horizontally across multiple servers. This makes them well-suited for handling the variety and velocity of Big Data.
Data Lakes and Data Warehouses
Data lakes and data warehouses are two different approaches to storing and managing large datasets. Data lakes are essentially large repositories of raw, unstructured data that can be used for a variety of purposes. Data warehouses, on the other hand, are more structured and organized, with data being pre-processed and optimized for specific use cases like reporting and analytics.
Data Processing Frameworks
To process and analyze Big Data, organizations use a variety of data processing frameworks like Apache Spark, Apache Flink, and Apache Storm. These frameworks allow for distributed processing of large datasets across multiple nodes in a cluster, enabling faster and more efficient analysis.
Machine Learning and AI
Machine learning and artificial intelligence techniques are increasingly being used to automate the analysis of Big Data. By training algorithms on large datasets, organizations can identify patterns and insights that would be difficult or impossible for humans to detect. This can help with tasks like fraud detection, predictive maintenance, and customer segmentation.

Best Practices for Big Data Management
To effectively manage Big Data, organizations should follow some key best practices:
- Define Clear Goals and Use Cases: Before embarking on a Big Data initiative, it’s important to have clear goals and use cases in mind. What insights are you hoping to gain? What business problems are you trying to solve? Having a clear roadmap will help guide your data management strategy.
- Establish Data Governance Policies: Data governance policies are essential for ensuring the quality, security, and consistency of your data. This includes things like data standards, metadata management, access controls, and data lineage.
- Invest in the Right Tools and Infrastructure: Choosing the right tools and infrastructure is critical for managing Big Data effectively. This may include distributed file systems, NoSQL databases, data processing frameworks, and cloud platforms like Amazon Web Services or Microsoft Azure.
- Build a Strong Data Team: Managing Big Data requires a team with a diverse set of skills, including data engineers, data scientists, and data analysts. Investing in training and hiring the right talent is essential for success.
- Ensure Data Security and Privacy: With the increasing focus on data privacy and security, it’s essential to have strong measures in place to protect sensitive data. This includes encryption, access controls, and compliance with relevant regulations.

The Future of Big Data Management
As data continues to grow in volume, velocity, and variety, the field of Big Data Management will only become more important. Some of the key trends and developments to watch include:
Edge Computing
With the proliferation of IoT devices and 5G networks, more and more data is being generated at the edge of the network. Edge computing allows data to be processed and analyzed closer to the source, reducing latency and bandwidth requirements. This will require new approaches to data management that can handle the distributed nature of edge data.
AI and Automation
Artificial intelligence and machine learning will play an increasingly important role in Big Data Management, automating tasks like data cleansing, anomaly detection, and predictive analytics. This will help organizations extract more value from their data while reducing the need for manual intervention.
Hybrid and Multi-Cloud Environments
As organizations move more of their data and workloads to the cloud, managing data across multiple cloud platforms and on-premises environments will become increasingly complex. Hybrid and multi-cloud data management solutions will be essential for ensuring data consistency, security, and portability across these diverse environments.
Real-Time Analytics
The ability to analyze data in real-time will become increasingly important for use cases like fraud detection, predictive maintenance, and personalized customer experiences. This will require new data processing and analytics technologies that can handle the velocity and volume of streaming data.
Conclusion
Big Data Management is a complex and constantly evolving field that requires a combination of technical expertise, business acumen, and strategic planning. By understanding the challenges and best practices of Big Data Management, organizations can unlock the full potential of their data and gain a competitive edge in today’s data-driven world.
FAQs
1. What is the difference between a data lake and a data warehouse?
A data lake is a large repository of raw, unstructured data that can be used for a variety of purposes, while a data warehouse is a more structured and organized repository that is optimized for specific use cases like reporting and analytics.
2. What are some of the key skills required for a career in Big Data Management?
Key skills for a career in Big Data Management include programming languages like Java, Python, and Scala, knowledge of Big Data technologies like Hadoop and Spark, data modeling and architecture, and data visualization and communication skills.
3. What are some common use cases for Big Data analytics?
Some common use cases for Big Data analytics include customer segmentation and personalization, fraud detection, predictive maintenance, supply chain optimization, and market research and forecasting.
4. How do you ensure data quality in a Big Data environment?
Ensuring data quality in a Big Data environment requires a combination of automated data cleansing and validation tools, data governance policies and procedures, and regular data audits and profiling to identify and correct errors and inconsistencies.
5. What are some of the key data privacy and security regulations that organizations need to be aware of?
Some of the key data privacy and security regulations that organizations need to be aware of include GDPR (General Data Protection Regulation) in the European Union, CCPA (California Consumer Privacy Act) in California, and HIPAA (Health Insurance Portability and Accountability Act) for healthcare data in the United States.
| Characteristic | Description |
|---|---|
| Volume | The sheer size of the data, often measured in terabytes or petabytes. |
| Velocity | The speed at which data is generated and needs to be processed. |
| Variety | The different types and formats of data, including structured, semi-structured, and unstructured data. |
| Veracity | The quality and accuracy of the data. |
| Technology | Description |
|---|---|
| Distributed File Systems | Allow data to be stored across multiple servers, providing scalability and fault tolerance. |
| NoSQL Databases | Designed to handle large volumes of unstructured or semi-structured data. |
| Data Lakes | Large repositories of raw, unstructured data that can be used for a variety of purposes. |
| Data Warehouses | More structured and organized repositories optimized for specific use cases like reporting and analytics. |
| Data Processing Frameworks | Allow for distributed processing of large datasets across multiple nodes in a cluster. |
| Machine Learning and AI | Used to automate the analysis of Big Data and identify patterns and insights. |
No responses yet